|
|
| Cisco's Unified Computing foray in DataCenters Click on IMEX Reports and Order Form for additional information. |
|
Full report available 23 March 2009 from IMEX Research/ Order Form Areas Covered: • Data Center Trends & Challenges • Cisco’s Foray into Data Center Infrastructure • Industry Dynamics and Drivers in NextGen DC Infrastructure • Unified Computing Technologies •Contemplated Products − Deep Dive • Navigating an ecosystem of Partners and Competitors • Issues & Pitfalls for Cisco • IMEX Research Opinion Data Center Trends & Challenges
Cisco’s Answer: "Create a VM-aware DC 3.0" and "Follow that VM" The rise of virtualization software has erased traditional boundaries among servers, storage and networking gear. Unified Computing is Cisco’s advancement of next generation data center that links all resources together in a common architecture to reduce the barrier to entry for data center virtualization. Compute and storage platforms are architecturally 'unified' with the network and the virtualization platform. Cisco’s expected blade server outfitted with virtualization software and networking equipment is meant to make the management of hundreds of virtual servers easier for customers. Through bundling software and different types of hardware together, Cisco hopes to keep the margins for the server product high. A Data Center administrator can no longer claim ownership over an application or a server nor has the visibility or control over a server or an application particularly when multiple VMs are constantly coursing through a DC without knowledge of its owner or its underlying hardware. While major benefits of adopting Virtualization was increased utilization of resources through creating multiple Virtual Machines and increased HA using VMotion and DRS, the pitfalls were increased with a number of challenges remained unharnessed.
To capitalize on the opportunity presented by the NextGen Data Center, Cisco Systems is ready to launch blade servers specifically tuned for virtualization that will leverage the latest hardware and virtualization technologies. By skipping a few generations of older technologies, Cisco will be entering the market with by far the densest and powerful blade servers and data center infrastructure than any existing on the market. As a large cabinet filled with servers, switches and storage systems, along with bundled virtualization and management software, Cisco’s product is in essence a mainframe built mostly out of standard hardware. Cisco has crafted a tight package that’s chockfull of software in the hopes of keeping the profit margins on the product high. Originally HP’s Virtual Connect product introduced in c-Blade Systems became an industry run-away success and a basis of its wrestling market shares from the original leader IBM. HP’s blade servers share rose from a low of 25% 4 years ago to over 52% presently. Virtual Connect allowed wire servers once and flexibly connect on the fly, various servers to different storage and network resources. Some reports on Cisco Blade Servers imply that one can use industry standard servers in case of Cisco. The new processors in Blade Servers from Intel targeted at the virtualization market emphasis on memory and networking bandwidth, the two of the biggest bottlenecks in virtualized systems. This possibly can give Cisco a leg up in the industry against soon to be rivals IBM and HP. For a product overview see relevant section below. For a comprehensive report, available 23 March 2009, click IMEX Research/ Order Form Cisco's Goals The bottlenecks on blades come from saturation of the network due to multiple VMs accessing through the same physical network - much more problematic then saturation of memory. Cisco’s Blade Servers are targeted to remove these bottlenecks of virtualization, at the memory and adapter levels. The faster Core i7 Nehalem processors and large amount of fast DDR3 memory will improve performance within the blade, and the connection to Unified Fabric will make it easier to move data in and out of the blade, as well as moving virtual machines around with VMware's VMotion. This makes those blades extremely agile on how they can move resources around. Cisco's goal with this launch is to fully virtualize the data center - networks, servers, and storage - all in one fell swoop, using high-end blade servers using lots of memory bandwidth Product Goals
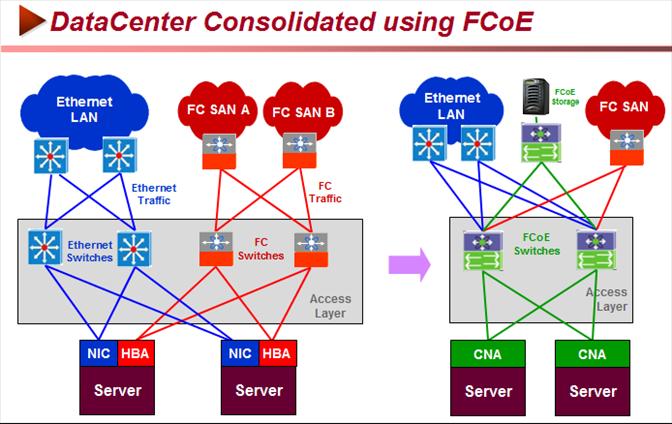
NextGen Virtualization Using Nexus 5000 the blades will talk directly to Cisco's Unified Fabric and are built to be virtualization-ready. The servers also feature tight integration with and support for VMware’s latest version of Virtualization software. With DC 3.0 Cisco will be using vSphere 4.0 to manage a data centre as a set of services used internally by a company or externally by service providers. vSphere 4.0 can trace every instruction executed on every server providing an extremely granular record for security and billing purposes. The architecture can also customize policies relating to security, availability and scalability. It enables data protection and clustering for availability, firewalls, anti-virus and compliance for security. In the future external clouds will be used to provide resource for extreme IT loads that are beyond the company’s internal capabilities or less critical with multi-tenancy keeping a customer's workload separate from other customers. One target is to have the ability to move VMs between internal site and external clouds using VMWare’s vCloud. Cisco’s Eco-system of Partners & Competitors in NGDC Cisco’s move stands as a direct assault on traditional partners like HP and IBM and will have the company competing for the data center as a whole rather than just the networking part. Could it evolve into creation of two camps in pursuit of an integrated NextGen DC namely Cisco, EMC/VMware, NetApp, Intel, BMC vs. Microsoft Hyper-V, HP, Avaya, Riverbed, and Intel? Cisco partnered with Microsoft, VMware, BMC, EMC and NetApp to participate at its new Unified Computing System product launch. The advantage Cisco has with California is that it is already the poster boy for networking has a vast gets into data centers and customers who already know and trust its products. If anyone can pitch an integrated server-storage-switch hybrid solution, all pre-integrated and ready to run virtualized applications, it's Cisco. Drivers for the NextGen Datacenter Infrastructure With Ethernet having achieved ubiquity in connecting millions of PCs to servers and the resultant dramatic cost declines of Ethernet adapters and switches have made SMBs and medium size enterprises to gravitate towards Ethernet-based infrastructure for networking and storage equipments. But the lossy nature of Ethernet of dropping packets when network congestion occurs has kept IT managers from running mission-critical business or high-performance technical applications in an all Ethernet-based storage to servers’ environments. As a result datacenters have resorted to three separate networks to meet the specific needs of different workloads – a Storage Area Network (SAN) that used a lossless fabric based on Fibre Channel (FC) Protocol which provided the necessary robustness and performance for storage to servers data traffic, IP for Network traffic and Infiniband (IB) for clustered high performance computing (HPC) requiring low latency. Further a new protocol called FCIP (a point to point wide area connection that tunnels between two FC switches over an extended IP link), allowed transporting FC frames over distances using IP-based networks. But the holy grail for datacenter designers has always been to design a network that can leverage the ubiquity of low cost Ethernet, be a single converged network that can carry both the network and storage I/O traffic with very different characteristics, be able to handle their different requirements efficiently to enable lowering the equipment costs and even more importantly lowering the management costs through by using single type of management tools that will simplify administrative tasks and training. Another requirement is to support block-based storage (vs. a file-based storage) that can provide flexibility of choosing latency vs. bandwidth metrics to meet performance, availability requirements of various workloads and yet be agnostic to the OS deployed. The NextGen Converged Enhanced Ethernet Network (CEE) Key to the unification of storage and networking traffic in NextGen DCs is a new Ethernet standard called Converged Enhanced Ethernet (CEE) that is being adopted by major suppliers. This new form of Ethernet includes enhancements that make it a viable transport for storage traffic and storage fabrics without requiring TCP/IP overheads. These enhancements include the Priority-based Flow Control (PFC), Enhanced Transmission Selection (ETS), and Congestion Notification (CN) and Energy Efficiency Ethernet Management (EEE). FCoE heavily depends on CEE. In the wake of this anomaly of different separate networks to meet the latency/bandwidth requirements of different workloads1 (OLTP, Business Intelligence, High Performance Computing, Web 2.0 etc – for incisive look see IMEX Report Next Gen Data Center Industry Report).
FCoE enables FC traffic to run over Ethernet with no performance degradation and without requiring any changes to the FC frame. It supports SAN management domains by maintaining logical FC SANs across Ethernet. Since FCoE allows a direct mapping of FC over Ethernet, it enables FC to run over Ethernet with no (or minimal) changes to drivers, SW stacks, and management tools. Network-only 10GbE does not have the same requirements around data qualification and interoperability that storage does, However, allowing FC and Ethernet storage traffic to run over a converged fabric requires significant work in order to make 10GbE Ethernet a lossless, native network layer. Although Ethernet already has some ability to isolate traffic using Virtual Local Area Network (VLAN) protocol, and service differentiation with the Quality of Service (QoS) protocol, however, Ethernet is still prone to network congestion, latency, and frame dropping – an unacceptable state of affairs for a converged network solution. The Ethernet " pause " frame was designed earlier in Ethernet for flow control but rarely implemented because it pauses the entire traffic on the link and fails the criterion of selective pause, set for converged network.
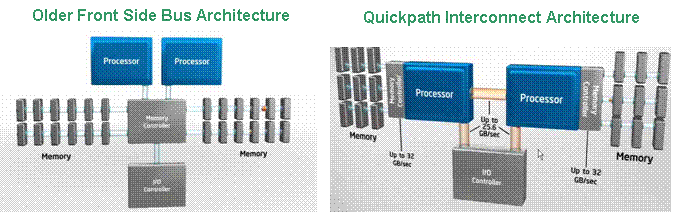
FCoE hosted on 10 Gbps Enhanced Ethernet extends the reach of Fibre Channel (FC) storage networks, allowing FC storage networks to connect virtually every datacenter server to a centralized pool of storage. Using the FCoE protocol, FC traffic can now be mapped directly onto Enhanced Ethernet. FCoE allows storage and network traffic to be converged onto one set of cables, switches and adapters, reducing cable clutter, power consumption and heat generation. FCoE is designed to use the same operational model as native Fibre Channel technology. Services such as discovery, world-wide name (WWN) addressing, zoning and LUN masking all operate the same way in FCoE as they do in native FC Storage management using an FCoE interface has the same look and feel as storage management as traditional FC product. Unified I/O Fabric for Unified Computing A Cisco unified fabric (like the Nexus 5000) sitting at the center of a web of interconnections. Blade servers running virtual machines link via 10Gig Ethernet to this switch and talk through it to storage, both block and file, and to the outside world. LAN, WAN and cloud. PCI Express connectivity (providing access to Cisco Unified Fabric Architecture with direct communication between the blades and the storage servers and a tight integration with VMware Storage arrays could be linked to the Nexus in this scheme by CEE and by FCoE later. For block access either iSCSI or Fibre Channel over Ethernet could be used. with FCoE as the enterprise access method and iSCSI as the SMB complement to this. FCoE interface arrays will qualify for a block access role. NetApp has a native FCoE interface capability for its storage arrays and can also provision both block and file storage from NetApp’s FAS products. Blade Servers Blades Servers will feature two Nehalem 5570 Xeons be based on Intel's Core i7 processors, with up to 384GB of memory, well above the maximum capacity of 128GB in today's blades. The blades include a PCI-Express connection, allowing them to connect to Cisco's high-speed Unified Fabric architecture. These connections also give the blades very fast Ethernet access to both the network and storage devices and eliminating the need for a storage-area network (SAN). Instead, the blades would talk directly to the storage servers. The blade servers are believed to come with Cisco's Nexus 5000 switches embedded in the chassis, which support the Unified Fabric, putting computing and networking power all in a single box and built to be virtualization-ready, The servers will also feature tight integration with and support for VMware software. The vast amount of memory would make it ideal for putting up to 100 virtual machines on the server, a problem blades currently have in that due to memory constraints, they can only run so many virtual machines. Core i7 has the new QuickPath Interconnect, which allows for much greater bandwidth than any prior x86 processors, greatly improving memory performance. After I/O, memory performance is the second biggest issue vexing virtualized servers. NextGen Nehalem Processors The new Nehalem processors, with the memory controller on the CPU and the QuickPath Interconnect (QPI), between processors allows the blades to access much more memory without choking. QPI has a bandwidth throughput of up to 32GB per second per link. The old Front Side Bus used in prior Intel processor- generations maxed out at 1.6GB per second.
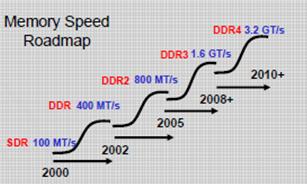
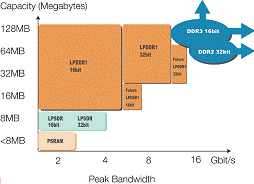
DDR3 vs. DDR2 Memory WMajor Features/Benefits of using DDR3:
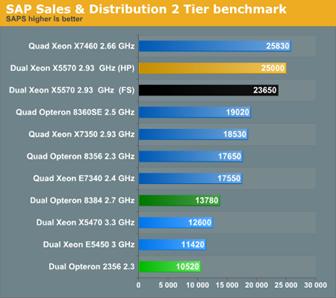
Performance Recent industry benchmarks (by Anandtech) running SAP performance test show on industry standard servers with Intel x5570 which runs at 2.93GHz, is 119 percent faster than the 3.3GHz xX5470, the top of Intel's current generation of quad-core Xeon processors.
10GbE Status 10GbE switch sales are rising, per-port costs are dropping, LOMs are beginning to appear on server motherboards, power requirements are being reduced, and major players are offering lines of affordable top-of-rack switches. 10GbE ecosystem is ready for mainstream adoption with 10GbE on the server motherboard and affordable SFP+ direct-attach copper cables for the typically short-distance interconnects between server and top-of-rack switches. Major drivers behind the rapid advance of 10GbE products include stabilization of the PCIe Gen2 standard and quick price erosion. 10GbE technology is available today in server NICs has started to migrate to LAN-on-the-motherboards. HP ProLiant BL495c G5 Server Blade already includes a dual-port 10GbE LOM. HP’s Virtual Connect Flex-10 allows you to divide a single physical 10GbE connection into four virtual connections, each tunable to different bandwidths in 100Mb increments. Top-of-rack 10 GbE switches that used to cost $2,000 to $4,000 per port two years ago now range from $400 to $900 per port now. Start up Arista Networks which uses10GbE chips from Fulcrum Microsystems, touts its top-of-the-rack switch sporting an extensible operating system at a compelling price/performance – 2-3x the 1 GbE prices but 10x the performance. Next Gen 10GbE CEE Adapters Emulex’s OneConneX, second generation CAN (combines Ethernet NIC and HBA functionality) currently supports up to three networks: Ethernet; Infiniband; and Fibre Channel optimized to run a variety of workload efficiently. iSCSI TCP/IP and FCoE stack processing are carried out on the card, which also performs processing for linking servers in an Ethernet cluster. SecureConneX HAB with RSA encryption and key management encrypts all traffic passing through the HBA at the server edge of the network instead of at the SAN level or storage device level and importantly at a key-per-virtual machine level allowing the crucial support for VMotion. Expect to see migration of encryption onto CNA technology over time. Cisco’s Nexus 1000V software switch similarly takes a VM’s network and security properties with it when the VM is moved around the data center. Go-To-Market:
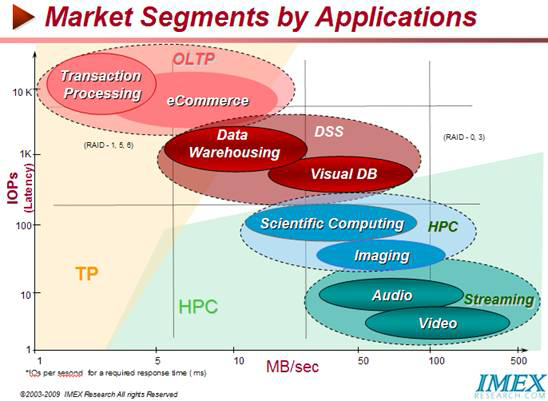
IMEX Research Opinion IMEX Research monitors several key metrics when evaluating technical aspects of a product from a company namely CAPSIMS: Primary (Cost, Availability, Performance) and Secondary (Scalability, Interoperability, Manageability and Security). Performance has two major metrics – Bandwidth (data transfer in Gbits/second) and Latency (to evaluate response time per online transaction processing for a given number of users online). These two metrics are key to measuring the efficacy of computing systems under different applications/workloads such as OLTP/Online transaction processing, BI/Business Intelligence/Data Warehousing, HPC/High Performance Computing/Numeric Intensive Computing, Web Streaming/Web 2.0/Audio/Video. Availability is inherent in the 3 R’s of Redundancy, Resiliency and Recoverability while Scalability and Interoperability are key in keeping Investment Protection over extended period. Data Management Automation/Ease of Manageability of all business processes visible and actionable through a single pane dash board integrating various workflows. Cisco’s heritage and mindset of Networking and IP Telecom keeps it thinking of performance measured by bandwidth and not transactions responsivity as has been the case of companies growing in the computing domain measured by TPMs or IOPs or latency such as IBM, HP, Sun, Dell, Fujitsu, EMC etc. while providing High Availability runs common to both groups of companies. It is for these reasons that EMC early on embraced Flash Solid State in their storage product line or IBM/HP chose quick tie ups with a leading startup (io-Fusion) to address the IOPs needs of computing. While Cisco realized the importance of Data Storage as a key holistic IT requirement of NextGen Data Centers and it has moved aggressively through some acquisitions, much remains for it to be fully conversant with, corral the intricacies of, and leverage the data storage business to its advantage, particularly given that cloud storage may turn out to be one of the biggest business in the next decade. Issues/Caveats Some of industry issues that Cisco will face on its march to Data Center 3.0 are:
|
| Click on the following for additional information or go to http://www.imexresearch.com
IMEX Research, 1474 Camino Robles San Jose, CA 95120 (408) 268-0800 http://www.imexresearch.com |