|
|
| The New ApplicationOptimized Virtual DataCenter Click on Executive Summary, Table of Contents and Order Form for additional information. |
| Next-Gen Application Aware Infrastructure
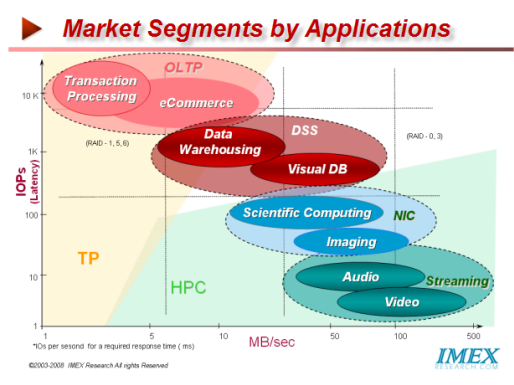
Creating a dynamic IT infrastructure that guarantees the performance and availability of critical applications both at the LAN and across the WAN to support remote locations and yet is changeable on-the-fly has been the holy grail that IT operations people have longed for and computer architects have targeted for over the years. The new trends towards data center consolidation, the convergence of voice, data and video over the same infrastructure, and the explosion in rise of TCP/IP traffic are all contributing to exacerbate the problem of application performance between clients at a far-flung branch offices worldwide (over 50% by some estimates) and shared data storage at the consolidated and virtualized data center at headquarters. Additionally with the rise of globalization and a number of organizations unable to keep IT organizations at every remote branch or remote sites, the importance of application-aware peak performance and availability takes on a stronger urgency. Applications Segmentation by Metrics
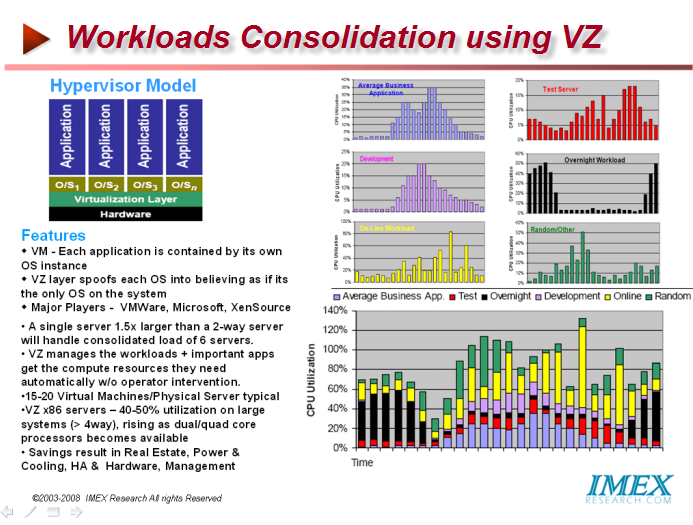
With the adoption of Virtualization, many applications run on the same server. A single server 1.5x larger than a 2-way server will handle consolidated load of 6 servers. Virtualization manages the workloads and important applications get the compute resources they need automatically without operator intervention.
Having 15-20 Virtual Machines per Physical Server is typical today with this ration rising as Data Centers become more comfortable with virtualization of all elements such as servers, networks and storage. Virtualizing x86 servers raises their utilization from typically 7-10% in yesteryears to 40-50% utilization today on large systems (> 4way), rising as dual/quad core processors becomes available. Savings result on many fronts including real estate, power and cooling, high availability and data management VMware provides an interface to manage and provision the shared disk resources. Without such an intelligent interface, the operational costs of scaling virtual machine workloads and their storage resources would be costly, reducing the financial benefits of virtualization. Next-Gen Data Centers – Beyond Virtualization Blades are here to stay; now the issue is how to control the ever increasing operating costs. Aside from data center design, it is equally necessary increase the utilization of resources already in place, and that is where virtualization provides a multi-dimensional solution. As the issue of power and cooling comes upfront,, companies are now carefully planning and implementing hot aisle and cold aisle design, ceiling plenums, racks with built-in cooling and supplemental cooling.
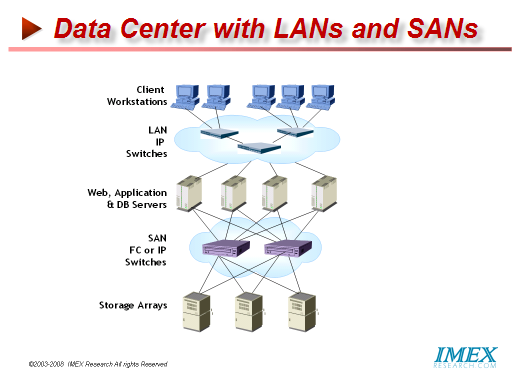
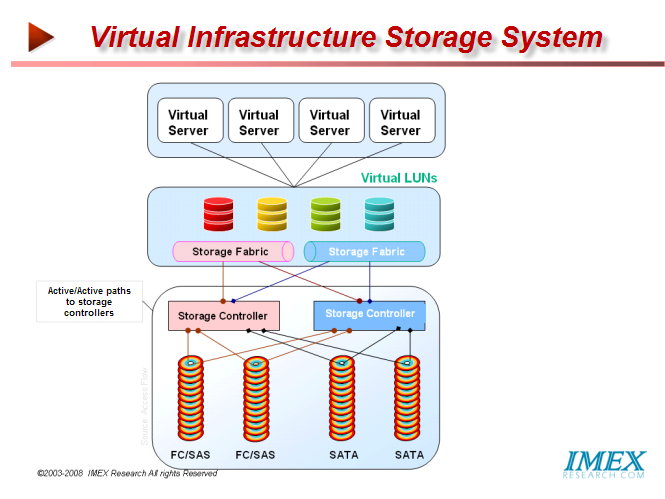
While a single application or appliance may not need enough bandwidth to justify a switch slot, multiple applications or virtual appliances aggregated together is another matter. While a traditional architecture might use a 16-port Gigabit Ethernet module to connect one switch to 16 servers, the virtual data center would put 16 virtual machines right on the Switch module. These VMs will have little relation to what we now think of as servers. For maximum flexibility, workloads must be able to move among servers--or switches--without necessarily dragging data with them, so they won't contain hard disks, relying instead on storage area networks. The same can happen to memory: It will migrate outside the server or VM, requiring a new type of network to link memory and CPU. Application-Optimized NextGen Data Center Infrastructure NextGen Application-Optimized Virtualized Storage For decades now, storage administrators have been fine tuning their computer systems’ performance through managing improvements in I/O by separating the storage systems from the multiprocessor complex and externalizing storage using channel interfaces and improving performance using caches. Other techniques used to enhance performance have command queuing, elevator seeking algorithms, look ahead architectures. Networked storage systems are the most complex and expensive part of a virtual infrastructure. The physical servers have traditionally been the main functional unit and focus of datacenter operations. Virtual infrastructures have commoditized servers to the point of being generic execution containers for virtual servers which can run on any of a number of physical servers in the infrastructure. Virtual of resources in memory, CPU, I/O Infrastructure management systems such as VMware’s VirtualCenter provide an abstracted management and control layer above the physical servers rendering them generic virtual machine containers. VirtualCenter provides for management of virtualized storage resources for the virtual machines; however there has always been considerable configuration, management, and tuning of storage resources at the physical layer Must be made before presenting to physical and then to Virtual Machine by the VirtualCenter. This renders the storage as both the most important yet most complex subsystem in virtual infrastructures. The Need for a Storage-Aware Hypervisor Storage administrators can best tune their storage for optimal performance if they could only ascertain the demands of the specific application running on the Virtual Server or in other words be Application Aware at all times thus avoiding the need for over-provisioning capacity while increasing utilization. By provisioning LUNs, on-the-fly, as required by an application, read/write performance of storage can be considerably enhanced while management is simplified and becomes more efficient when disk array resources are automatically assigned per LUN or File System, on-the-fly as required by an application running at that time. Thus Virtual machines in a Virtual Infrastructure must define optimal storage attributes or services for every application prior to creating a LUN, i.e. create a Smart Virtual Storage (SVS) profile that ties storage performance, cost and availability metrics to application/workload requirements. The key features of VMware like VMotion, HA, and DRS are enabled by the ability for all machines to dynamically access shared resources such as networked pool of storage usually in a SAN. Shared storage resources are provisioned on the fly to meet specific needs of the application just as you provision your servers-extending the benefits of server virtualization. Virtual infrastructures have a very different storage profile than most traditional workloads. Capacity expansion is driven by adding virtual servers. Maintaining multiple virtual disk files in each LUN combined with the resource time sharing inherent in virtualization results in increased random disk I/O with each virtual server added to the infrastructure. Traditional mid-range storage arrays with shared loops and storage controllers for all disk shelves often see resource contention as load and capacity increase. Disk level performance tuning cannot overcome the limitations of congestion on shared controllers and data paths. A Virtual Infrastructure Storage System must provide the ability to scale performance linearly with virtual server growth. QoS Management VMWare’s Distributed Resource Scheduler (DRS) does the CPU and Memory QoS Management Assigning QoS levels by LUNs can be utilized to configure high performance systems such as database and exchange servers with high Quality of Service (QoS), medium QoS levels for standard production or back-end services including print servers, file servers, and infrastructure monitoring systems while lower QoS LUNs are utilized for test systems, archive disks, template servers and other less response critical systems. QoS levels can also be used to provide the required data protection, level of redundancy/ availability to be set at the LUN level. Standard (RAID-5), Dual (RAID-1) or Triple (RAID-6) protection can also be accomplished per Application or VM allowing loss of multiple disks without data loss. This approach to managing a range of service quality across commodity disks is far more effective and economical than storage systems that manage performance by using expensive high performance disks for all virtual servers, or use high capacity SATA drives with no way to manage performance within the multi terabyte RAID sets. Applications that are layered on a single server generate I/O requests to the shared storage pool that appear to be random. The more of these non-virtualized applications that access the system, the greater the randomness of the disk access and the greater the strain on the shared storage device. This I/O pattern can overwhelm a storage subsystem. A key to storage management in a virtual infrastructure is to balance the I/O requirements by provisioning your storage. Ideal Storage Density Having high data density storage (i.e. few spindles with high capacity) lowers the cost of storage but severely limits disk drive utilization to around 30-40%. On the other hand having low density storage (large number of spindles each with low capacity) avoids overtaxing the storage systems and mitigates load imbalances and disk access contention, not knowing which workload might create the peak I/O load on a particular disk drive driving the service times beyond acceptable levels, but dramatically raises the total cost of storage. Much as implementation of RAID storage distributes the load over multiple disks removing disk access hot spots, shared storage in virtual infrastructure environments have different issues to wreck with. With server virtualization each physical server gets partitioned into multiple virtual servers (VMs). Each VM runs multiple applications and includes CPU, Memory and storage resources allocated to it. Since storage is shared by multiple VMs, they are now demanding more I/O from the shared storage systems, causing much more strain on a storage system than the same number of non-virtualized servers. Virtualization Infrastructure requirements create a more demanding storage environment such as requiring shared storage SAN. Additional licenses and even new SANs are required to resolve performance degradation created by the non linear performance characteristics of scaling capacity in traditional storage arrays. Given the functional inseparability of virtual servers and shared storage, the full potential and savings of virtualization can only be realized when the storage system is optimized and managed as a single functional unit within the virtual infrastructure. The storage related barriers to virtual infrastructure implementation include acquisition and expansion cost, manageability, and complexity. Traditional storage management is usually much more structured, controlled and deliberate, but Virtual Infrastructure management is dynamic. Ideally the virtual infrastructure should extend its boundaries to include both the physical and logical storage. Storage Management features such as quality of service, data migrations, snapshots, and LUN management are key to overall virtual infrastructure management.
Virtual infrastructure management systems such as VMware’s VirtualCenter supply robust quality of service features to maintain desired service levels across different priority workloads running on shared hardware. VMware’s Distributed Resource Scheduler provides granular effective controls over server CPU and memory resource shares and limits; however, there is no effective way to manage disk access performance levels from within the standard virtual infrastructure management systems. To maintain true quality of service within a virtual infrastructure, the storage systems must be able to differentiate and manage performance across different virtual server workloads. For storage quality of service to be effective, performance must be managed both at disk access, and in the storage controllers. Virtual infrastructure administrators should be able to manage storage quality of service as easily and non-disruptively as CPU and memory QOS administration. Managing performance on traditional arrays is typically done at the physical disk RAID level and is not easily or non-disruptively changed. A virtual infrastructure storage system must provide enhanced availability and reliability if it is to be used to host large numbers of production servers. Short disk rebuild times, the ability to withstand multiple disk failures, and non-disruptive component replacement and capacity expansion are a must for a viable virtual infrastructure storage system. Virtualizing storage by creating LUNs from a common unified pool of storage and presenting to the virtual infrastructure helps create a unified virtual infrastructure where virtual servers, storage, and networks are all created and managed in real time thus providing it the simplicity and flexibility native to virtualized infrastructures. Using a good storage system with a virtual infrastructure can eliminate the need for dedicated storage management staff, providing savings that can exceed the cost of purchasing a SAN itself. An ability to provide FC drive performance but utilizing high performance SAS and high capacity SATA disks under a universal controller can dramatically reduces costs compared to traditional arrays. Thus creating a Storage System that is tunable on-the-fly to optimize the performance and availability applications increases the value of virtual infrastructures dramatically. Additionally if it is scalable to address a variety of markets from small to large enterprise data centers, it can provide cost optimization and investment protection. Some of the best practices for storage virtualization have been nicely listed by Pillar Data as follows:
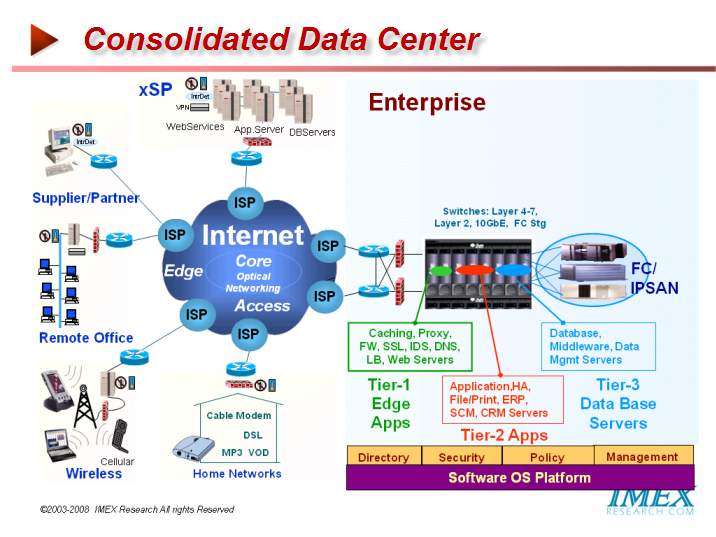
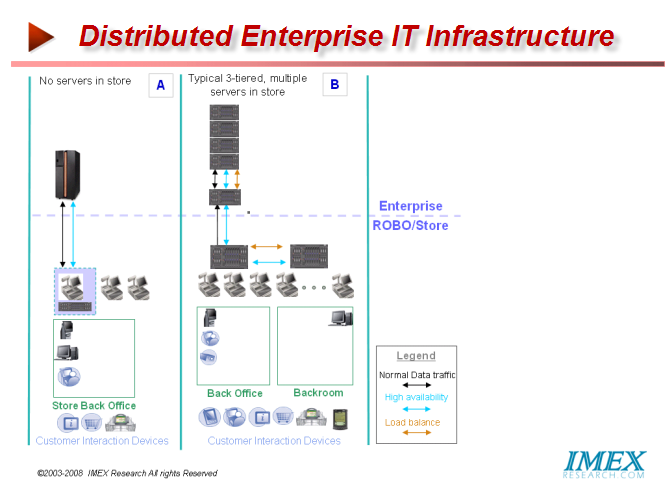
Pillar Data claims its Axiom 500/600 to be one of the most efficient storage systems saving up to 75 percent of the energy required to power and cool most storage infrastructures using capacity consolidation and driving greater disk utilization and performance optimization. This efficiency is created through consolidating the capacity and tiers of what traditionally would be multiple arrays into a single system driving greater disk utilization. Pillar does not have hidden software license charges. All features in the Axiom storage systems are included with the hardware. Quality of service, snapshots, file replication and multipath functionality are included with the system. Scaling the system with additional bricks or Slammers does not incur additional licensing fees. Application Aware Networks In recent years, telecom operators have been forced to revisit their strategies in light of emerging trends of lower-margin IP data traffic has begun overtaking higher-margin voice traffic as VoIP’s fast adoption accelerates the transformation of voice traffic into data traffic and of eroding margins from private networks to less costly TCP/IP-based networks such as the cost of bandwidth declining steadily and their clients migrate toward Multi-Protocol Label Switching virtual private networks. The carriers are reacting to these changes by rolling out triple and quadruple play strategies - selling bundles of voice, data and video - and now mobile communication services. Other approaches they have taken is to offer different Classes of Service (CoS). Application-aware networking products are not the same as Layers 4 to 7 switches, or content networking products. Such products typically switch on specific fields in the HTTP header, but they don't look into the application-layer payload itself. Application intelligence can be distributed across multiple network-based platforms by application-layer routing protocols. In principle, these systems are simpler from an operational perspective because the use of dynamic routing protocols at the application layer provides auto-provisioning of new users and services without extensive manual configuration. CoS addresses the issue of undifferentiated treatment of application flows by assigning different applications to different classes. Flows assigned to a higher class will get dedicated bandwidth and will spend less time in congested router queues. As a result, higher class traffic will have lower transfer delays and packet losses. Inherently CoS is a simplistic approach simply because it aggregates into a single class several applications. These applications or multiple sessions of a same application then compete for bandwidth in the same class, leading to congestion and poor application performance. Further, it only tackles the issue of bandwidth allocation. But other issues such as latency, which are not directly bandwidth dependent, can cause application performance problems. Further it is only a static approach to optimization because the sizes of the classes of service and the mapping of applications in different classes are decided at the onset of the service. However traffic conditions change quickly with the addition of new users, new applications and new sites and the originally set CoS configuration usually become quickly obsolete and unoptimized. The real solution lies in becoming application aware directly and then automatically linking application performance objectives on-the-fly with network resources, albeit all elements of the Virtualized Server container - OS, CPU, Memory, Storage and Network Bandwidth and latency allocation dictated by an application. With such a system in place, enterprises and carriers could finally provide the holy grail of optimized application delivery to their clients - an application-aware infrastructure that could offer Application Service Level Agreements guaranteeing application performance, availability, cost and manageability. At the most basic level, application-aware networking refers to the intelligent network-based processing of application-layer content. By embedding functions currently done in middleware server software into router silicon gives the router sight of what is actually moving through the network, and therefore being able to route it according to what it contains thereby gaining effective speed and scalability. This enables the network to classify and prioritize content based on specific application-layer attributes – for example, contracts and high dollar value purchase transactions, reading a food-service order to route it to the correct airport terminal. Carriers demanding very high service availability will be able to choose routing having high-availability features such as active/active failover. Application-aware networking devices can also communicate this classification to the underlying IP network via mechanisms like DiffServ code points or 802.1p bits. For example, this allows the service providers to offer different QoS for different traffic content reflecting the importance and priority dictated by the sender (so bills and tickers get through fast, and illegal or tire-kicking downloads get lost). Also the multicast content push services could be handled directly by the network, rather than by server farms. This also allows service providers to monetize the flow of message traffic through application-layer billing capabilities. Content Aware Networks also allow service providers to distribute content closer to the end user and overcome issues such as network bandwidth availability, distance or latency obstacles, origin server scalability, and congestion issues during peak usage periods. Application intelligence can also be distributed across multiple network-based platforms by application-layer routing protocols. Cisco, Juniper Networks, Microsoft,3COM, IBM and a host of start ups are addressing these areas with new products. NextGen DataCenters by Vertical Markets Given the emergence of globalization, there is perceptible rise in branch and remote offices, albeit in Banking, Finance, Retailing, Airlines or a host of other eCommerce based vertical markets.
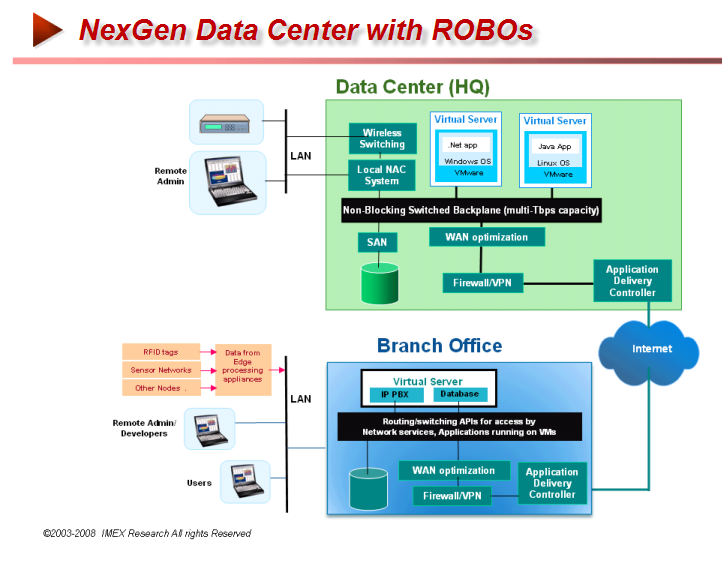
A typical example of NexGen Data Center consolidated into fewer datacenters and implementing latest Blades Infrastructure while connecting to multiplicity of Remote/Branch Stores in the Retail Industry as shown creates the need for Application Optimization as well as Application Acceleration on WANs connecting between HQ and the branches.
NextGen Data Center Report 2008 Targeted for vendors, system integrators, CIOs/DataCenter Operations as well as Investment/VC groups, this latest report from IMEX Research provides an exhaustive insight into the emerging technologies, solutions and best practices applicable to reduce the overall costs when implementing the newest generation Data Centers.
|
| Click on the following for additional information or go to http://www.imexresearch.com
IMEX Research, 1474 Camino Robles San Jose, CA 95120 (408) 268-0800 http://www.imexresearch.com |